Language Games With Machine Learning
July 03, 2020
Code
In 1948, Claude Shannon published A Mathematical Theory of Communication, which introduces some math for thinking about how to set up a communication system. To communicate a message correctly from person A to person B, we don't want to lose any of the important "information" in the message.
But information theory is only one tool for thinking about natural language. Information theory is very mathematical, but it's not obvious that everything in semiotics can be represented mathematically.In the real world, the systems we use to communicate information tend to be called protocols or languages. For example, TCP is a protocol for passing information through the Internet, and natural languages like English are spoken so that we can pass information along to other people. Communication systems can be designed, or they can emerge spotaneously and evolve over time — like most spoken languages. This observation begs the question: "Could we design environments which encourage novel communication systems to emerge and evolve?"
To guide this exploration, we can borrow a helpful tool from information theory. The Shannon-Weaver model describes the basic elements in any communication system, whether it's a language, compression codec, or electronic signal:
- An information sourcethe message we want to communicate
- A transmittera process for representing that message
- A channelhow the message is represented as it travels from the source to the destination
- A receivera process for reconstructing the message
- A destinationthe message that was received
Via optimization, artificial neural networks can be tuned to transform information from one form to another. An autoencoder is notably one differentiable implementation of the Shannon-Weaver model. The input and the output of an autoencoder are the same. The encoder weights learn to transmit a signal, and the decoder weights learn to reconstruct a message. The interesting part of an autoencoder is what is called the bottleneck, or latent space, which lines up with the idea of a communication channel. The latent space is a transformed (and often compressed) representation of some input, which the autoencoder learns to reconstruct as accurately as possible on the other end.
The latent space of an autoencoder is usually an uninterpretable vector code. I got interested in exploring how adding constraints can make these systems generate patterns that are more visually appealing. These could have a whole lot of interesting use-cases such as generating highly readable fonts, turning source code into pictures, or transforming entire sentences or paragraphs into abstract images. Joel Simon did some really interesting experiments with generating writing systems in 2018. His project inspired my initial curiosity.
One straightforward idea would be to generate an alphabet of a particular size. For an alphabet with 10 characters, one can train an autoencoder to produce 10 unique visual patterns. The inputs and outputs are simply the numbers 1-10 (as one-hot vectors), and the latent space is an image. The loss function should encourage the autoencoder to reconstruct the original message by accurately predicting what the input was, based on the image. We can do this with a simple cross-entropy loss which encourages the predicted message to match the input message.
If we add some constraints to the latent space such as rotation or blur, we'll get patterns that are more coherent and distinct. This is a simple way to try making the alphabet more humanlike and interesting. If you tilt your head or squint your eyes, you can still read the letters in a word, because written languages are robust enough to a survive bit of blur and rotation.
The resulting system contains an encoder, which takes a message and turns it into an image, as well as a decoder, which takes an image and predicts its message. Based on the design of Joel Simon's experiment, Ryan Murdock first called these systems Cooperative Communication Networks.

The result of training an autoencoder this way may look like this:

These generative systems grow in complexity in proportion to the complexity of the environment that they are generated in. We can set additional constraints on the communication channel to encourage more interesting patterns to emerge. We could also define different kinds of messages beyond simple alphabets to represent visually. It seems that there's a huge space of constraints and objectives one could experiment with, with many interesting patterns to be generated!
Attempting To Learn A Math Notation System
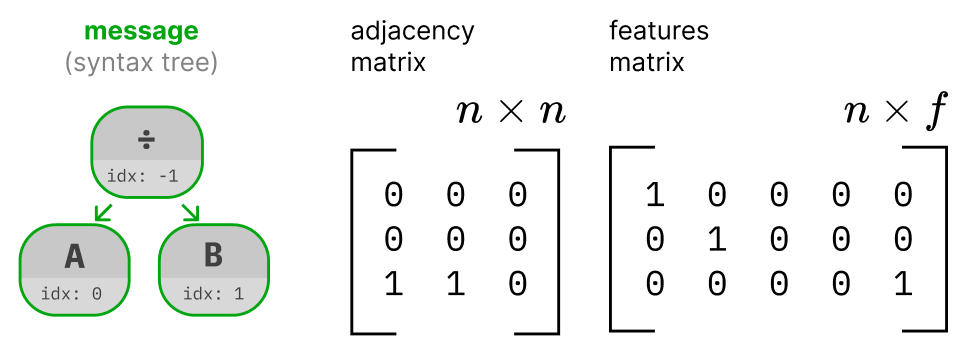
One kind of message I enjoyed experimenting with was arithmetic expressions. I was curious if an autoencoder would, by turning syntax trees into images, learn a kind of mathematical notation system. Just like with a simple 10-character alphabet, we can train an autoencoder to learn representations of the message by defining a reconstruction loss function. The loss function for reconstructing syntax trees is a little trickier. A syntax tree predicted by a graph autoencoder (GraphVAE) is based on an adjacency matrix and a set of node feature matrices (in this case there was one for node type and one for node order.) So, the message is a collection of one-hot matrices that are predicted all at once by the graph decoder.
Calculating the loss for GraphVAE is a little more complicated than this because a prediction could be isomorphic but unequal to a message and still be completely valid. We need to do graph matching before calculating the loss. If you're interested, see section 3.3 of GraphVAE for more details.This model predicts both the adjacency matrix and node feature matrix representing a syntax tree. The two prediction loss scores are summed together to give the full reconstruction loss (with an additional trick to admit permutation-invariance of graphs.)