Rough experiments in feature audiation
July 05, 2021
Code
Feature visualization shows us that there are a collection of tools and techniques for interpreting machine learning models trained on images. When applied to computer vision networks like VGG or ResNet, we get a variety of visual patterns, textures, and abstract artifacts.
Because of some inherent difficulties, similar techniques aren't often transferred to models of other kinds of data. For example, text is less straightforward: BERT is a "bad dreamer." And it appears that feature visualization for audio has its own set of challenges. Given that audio models perform very well and are increasingly used in practice, it could be valuable to adapt existing visualization techniques to the class of audio models and see what might happen.
Modeling Speech With Wav2Vec2
There are a lot of kinds of audio models. While both music and speech are sources of training data, I decided to use a model trained on speech only. I also picked an encoder model rather than a generative or autoregressive one, because it is more straightforward to adapt to feature visualization.
One of the most recent architectures for speech processing is Facebook's Wav2Vec2. Wav2Vec2 starts with a handful of 1D convolutional layers followed by a transformer encoder. It was trained on 53,000 hours of unlabeled speech, and its weights are made available via fairseq or HuggingFace.
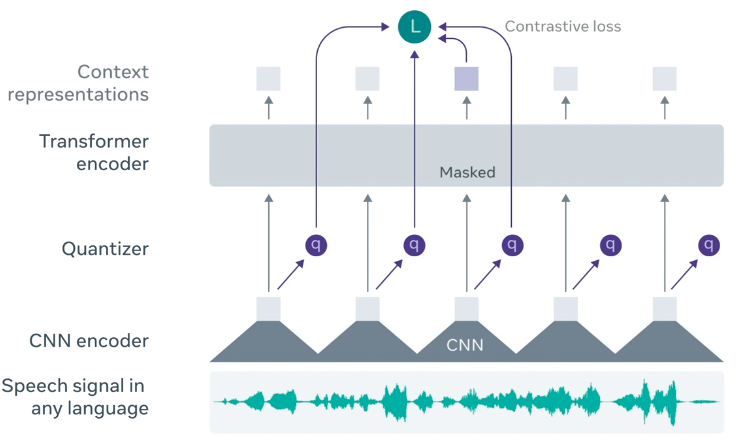
We can think of Wav2Vec2 as a general algorithm for converting a waveform of speech audio to a stream of lower-frequency contextual representations where, in the case of Wav2Vec2-base, and . Thus, because the model is trained on audio sampled at 16 kHz, its output is a sequence of 768-dimensional vectors at a rate of 50 Hz (every second of audio has 50 corresponding vectors, or a vector for every 20 milliseconds.) It was trained similarly to a masked language model, where some inputs to the transformer are masked out and need to be predicted in context of the remaining inputs. But unlike language, speech doesn't come in discrete tokens, so there's an additional learning objective towards producing diverse discrete codes representing each section of audio.
These representations are useful for various tasks. For example, one may fine-tune Wav2Vec2 for speech recognition by mapping its output to characters of an alphabet or a dictionary of phonemes, via Connectionist Temporal Classification.
Optimization techniques
Importantly, images and audio can both be converted to the frequency domain via a Fourier transform. In images, it's been found that generating samples from the (power-normalized) frequency domain tends to produce better results than optimizing directly from the spatial domain. I found that this is also true for audio. It is also helpful to "augment" the samples with different kinds of transformations, making them more robust. We get improved results by representing inputs through the following pipeline:
- Random frequencies: generate a random normal distribution in the frequency domain.
- Normalize: multiply each frequency coefficient by the reciprocal of its corresponding frequency. (See
normalize_freq_coeff) - Convert to time domain: apply the inverse Fourier transform to produce a signal in the time domain.
- Augment: apply data augmentation to generated inputs: small left-to-right translation and elementwise Gaussian noise. (See
augment_signal)
Unit and Channel Audiation
Using this technique, we can optimize individual units of Wav2Vec2 with generated samples. Unit audiation is when we maximally activate a unit from a particular vector while discouraging activations of its neighbors. This is done for one specific point in time, while silence is encouraged elsewhere.
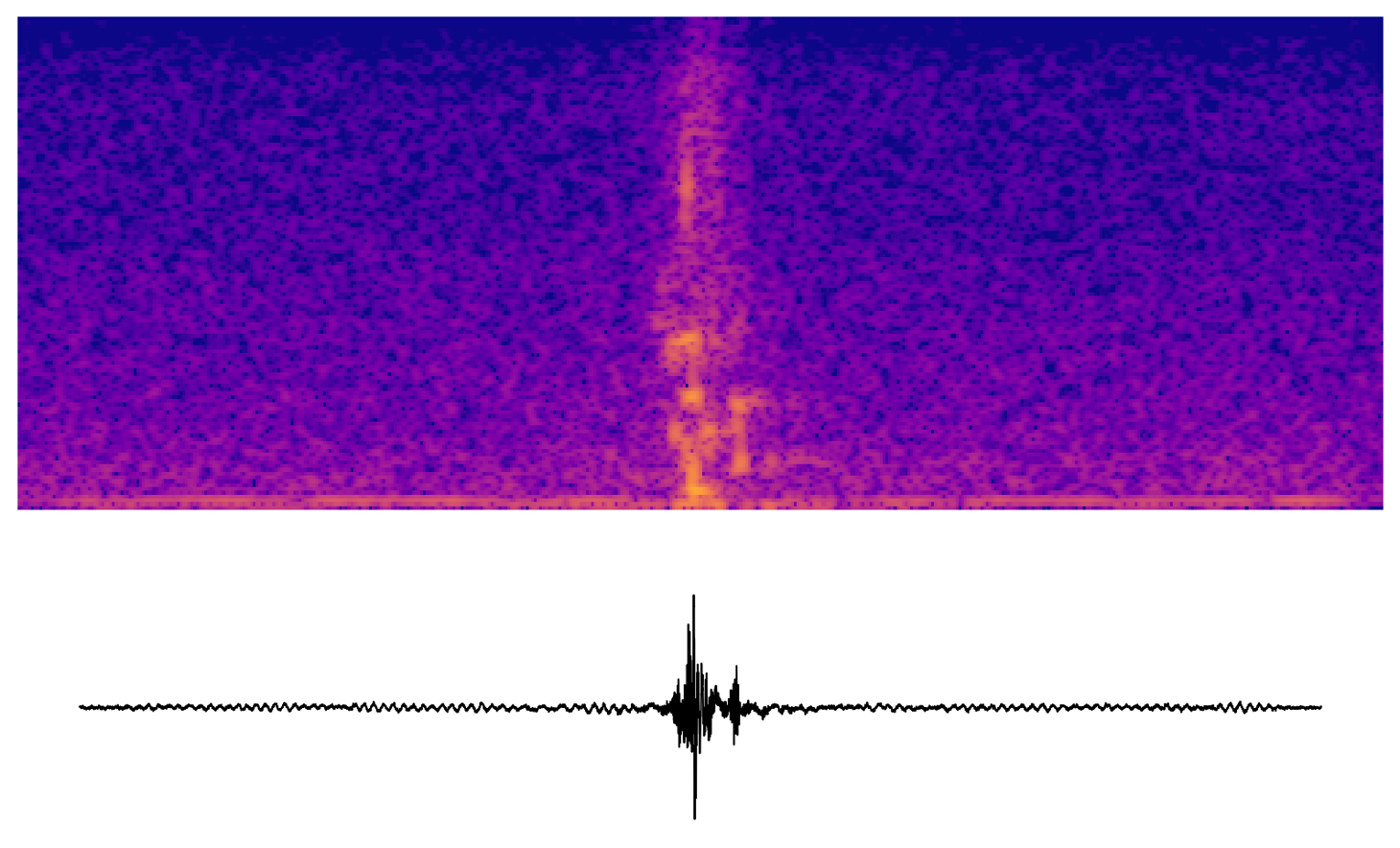
Early units
It was easier to focus on the transformer module of Wav2Vec2, so I start with the early layers of the transformer. The audiations here sound faintly speech-like. Maybe they represent phonemes or facets of phonemes.


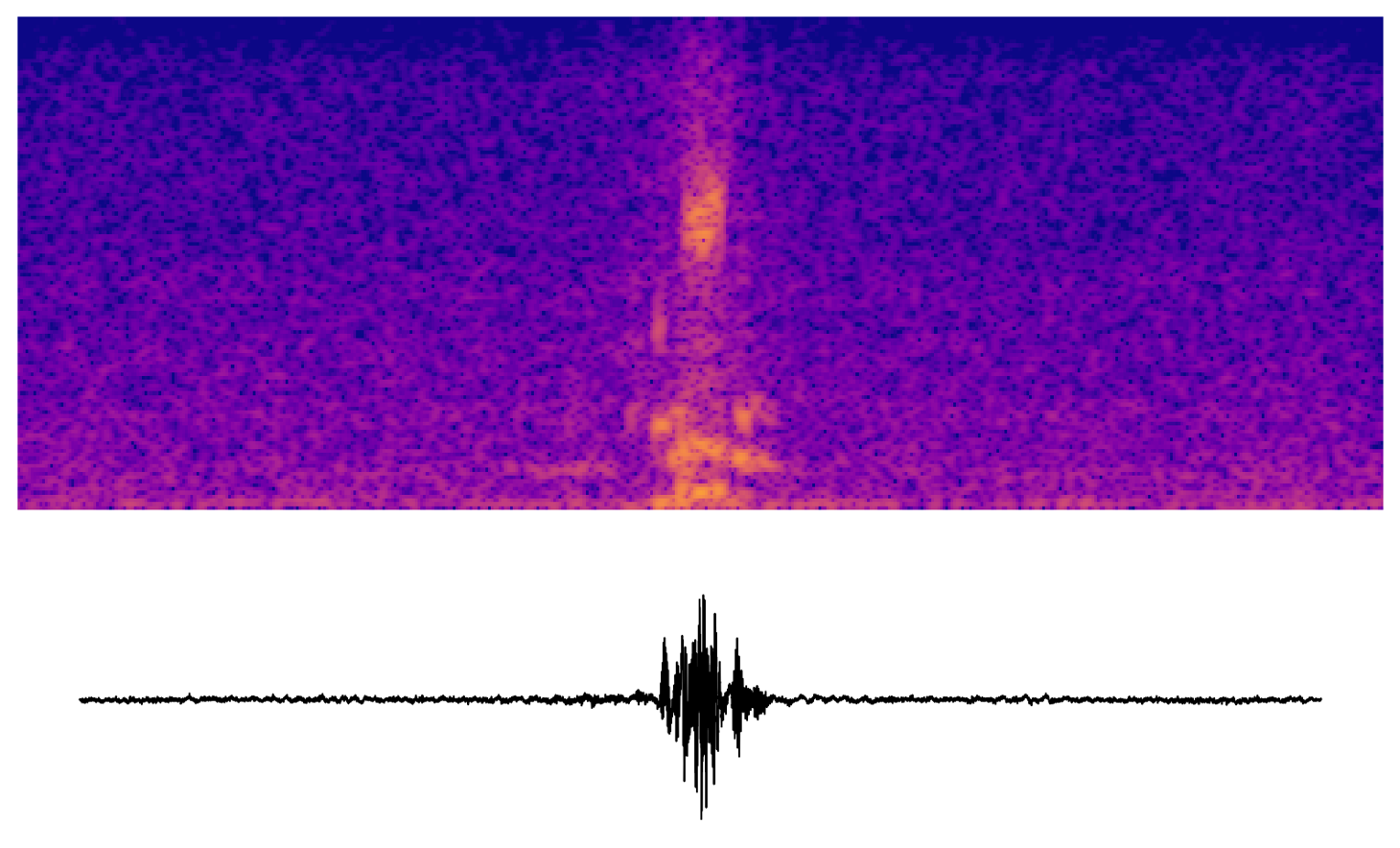
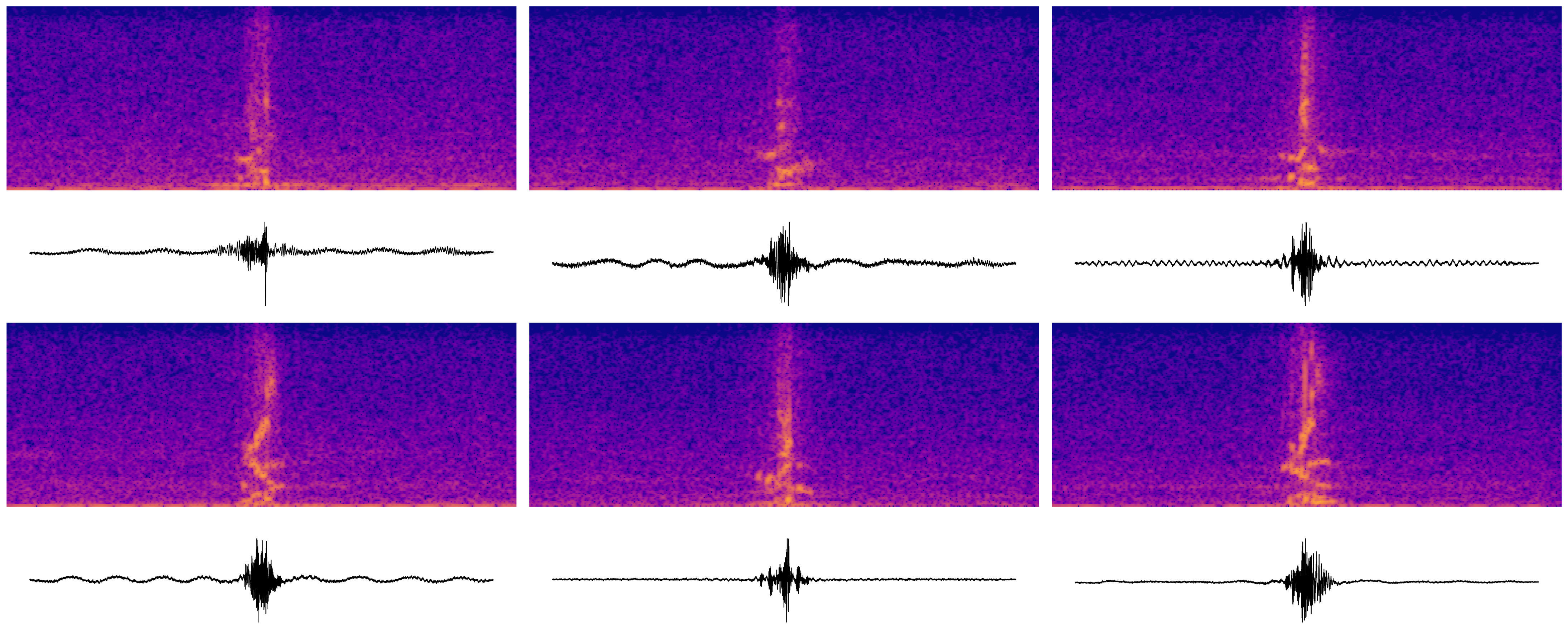
Later units
The transformer in Wav2Vec2-base has 12 layers. These are some samples taken from the latter half of the transformer.


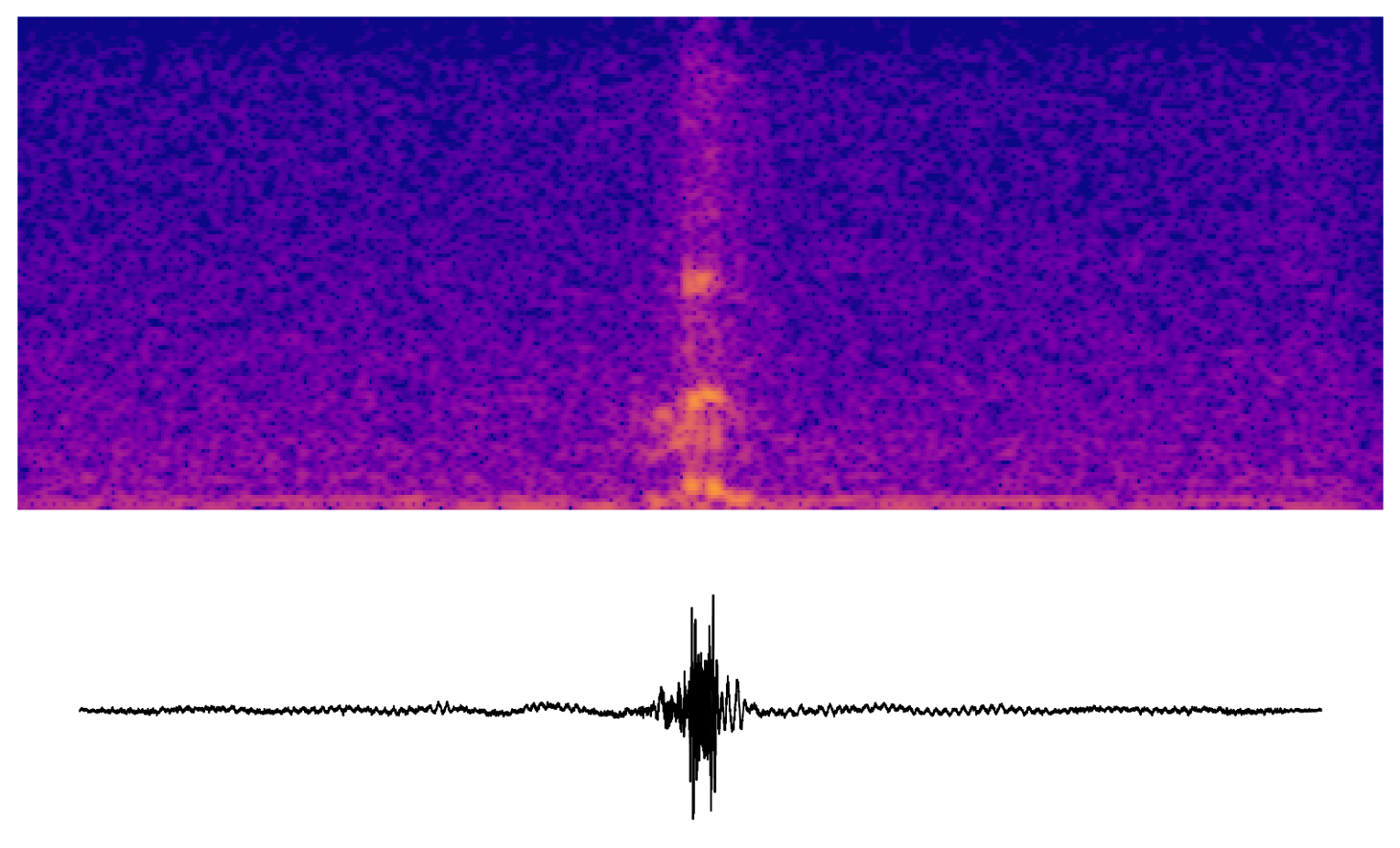
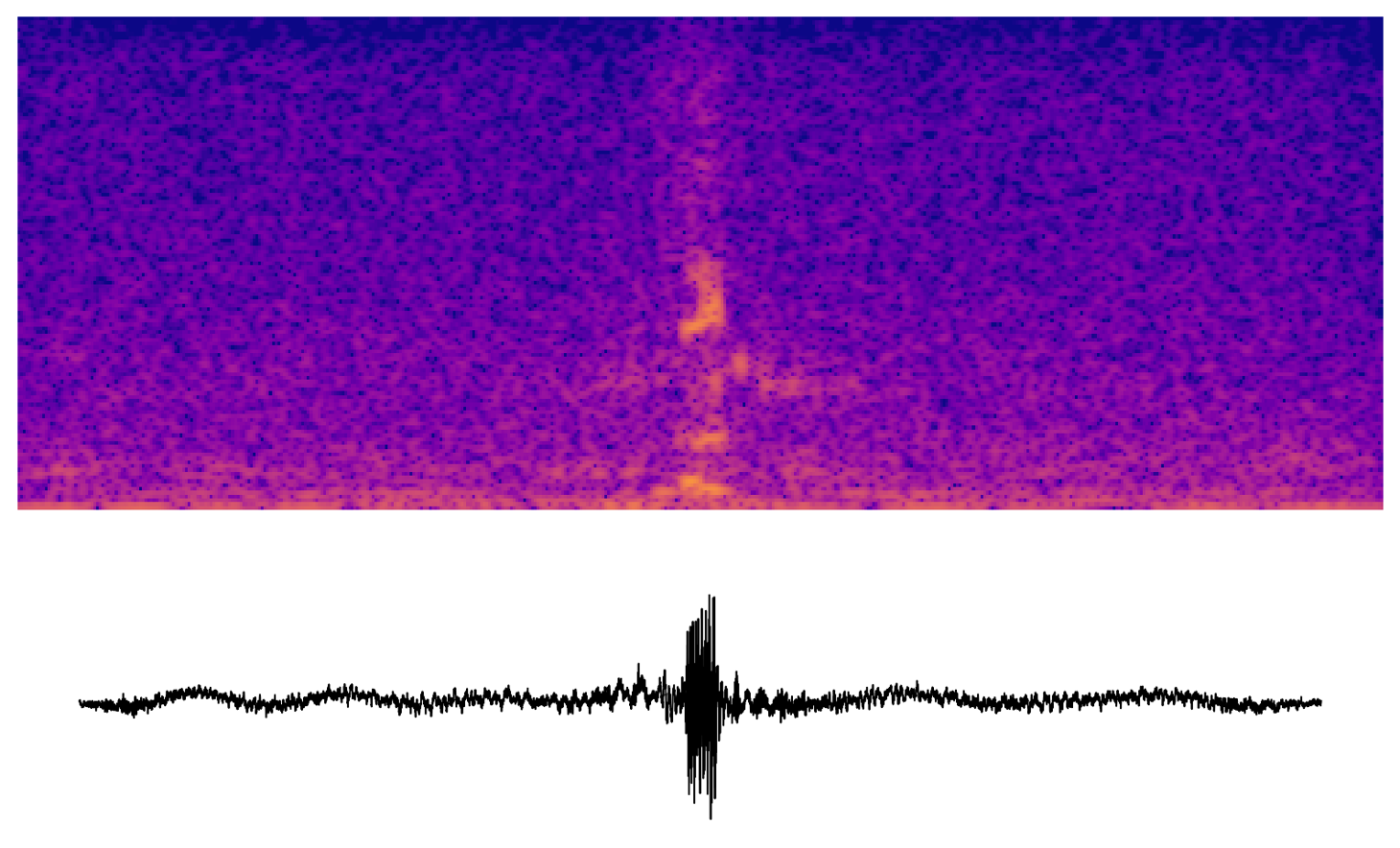
Channel audiation
A closely related technique is channel audiation, where a particular unit is maximized along the spatial (or time, in the case of audio) axes. In images, this technique generates abstract, but well-structured textures. In this early experiment, we get chaotic sounds with some repeating features. There's something eerie or comical about the humanness of some of these "audio textures."
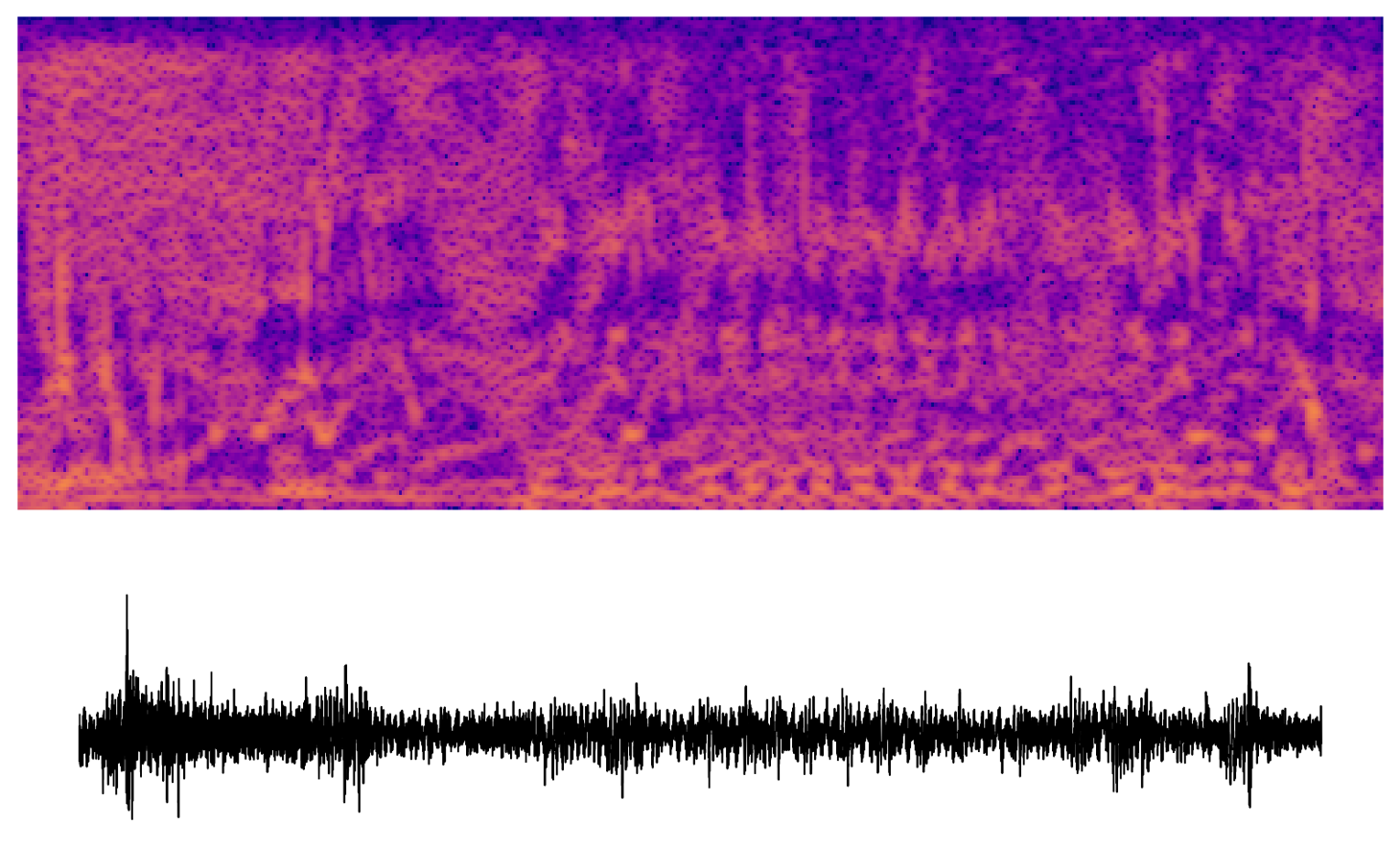
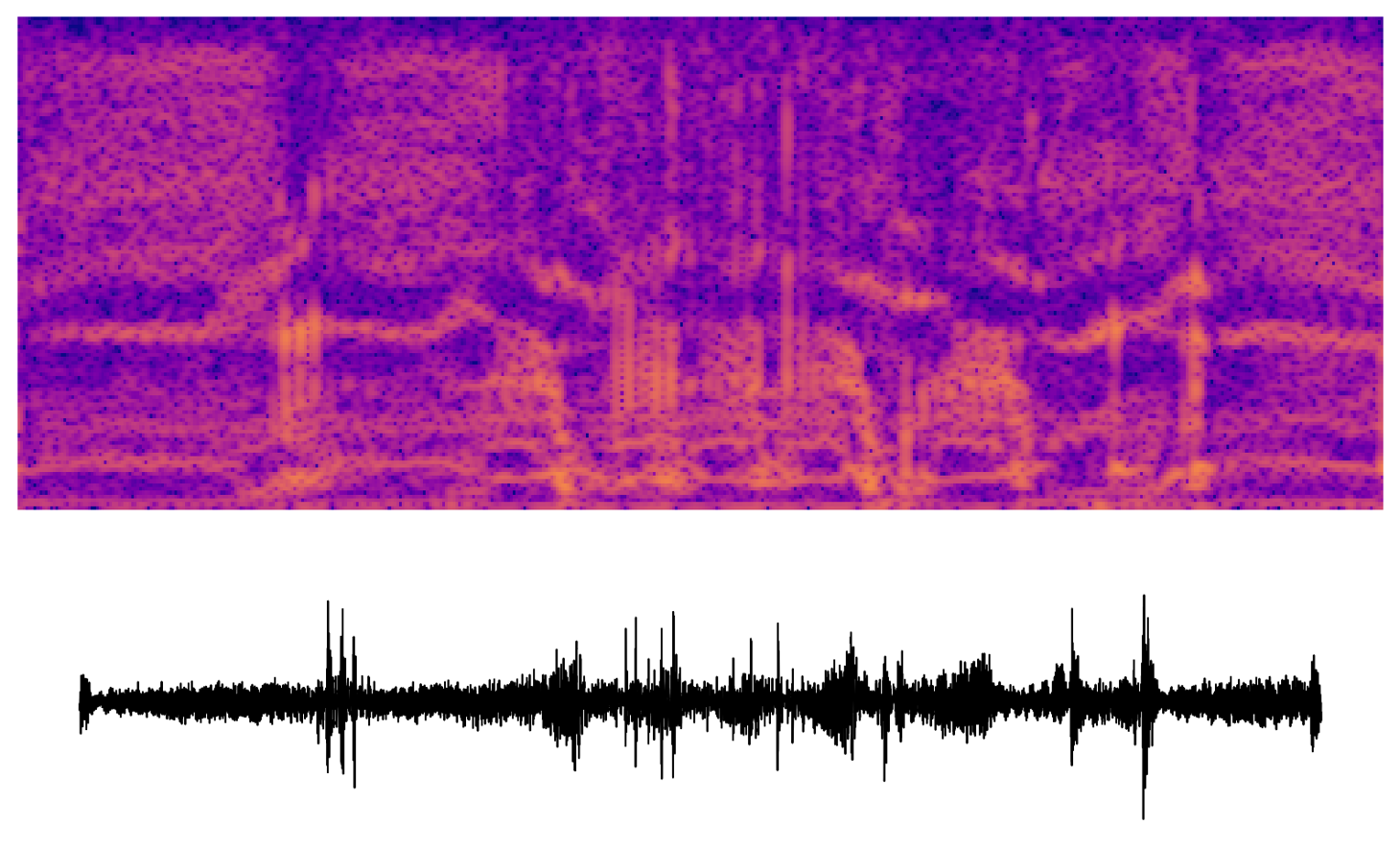
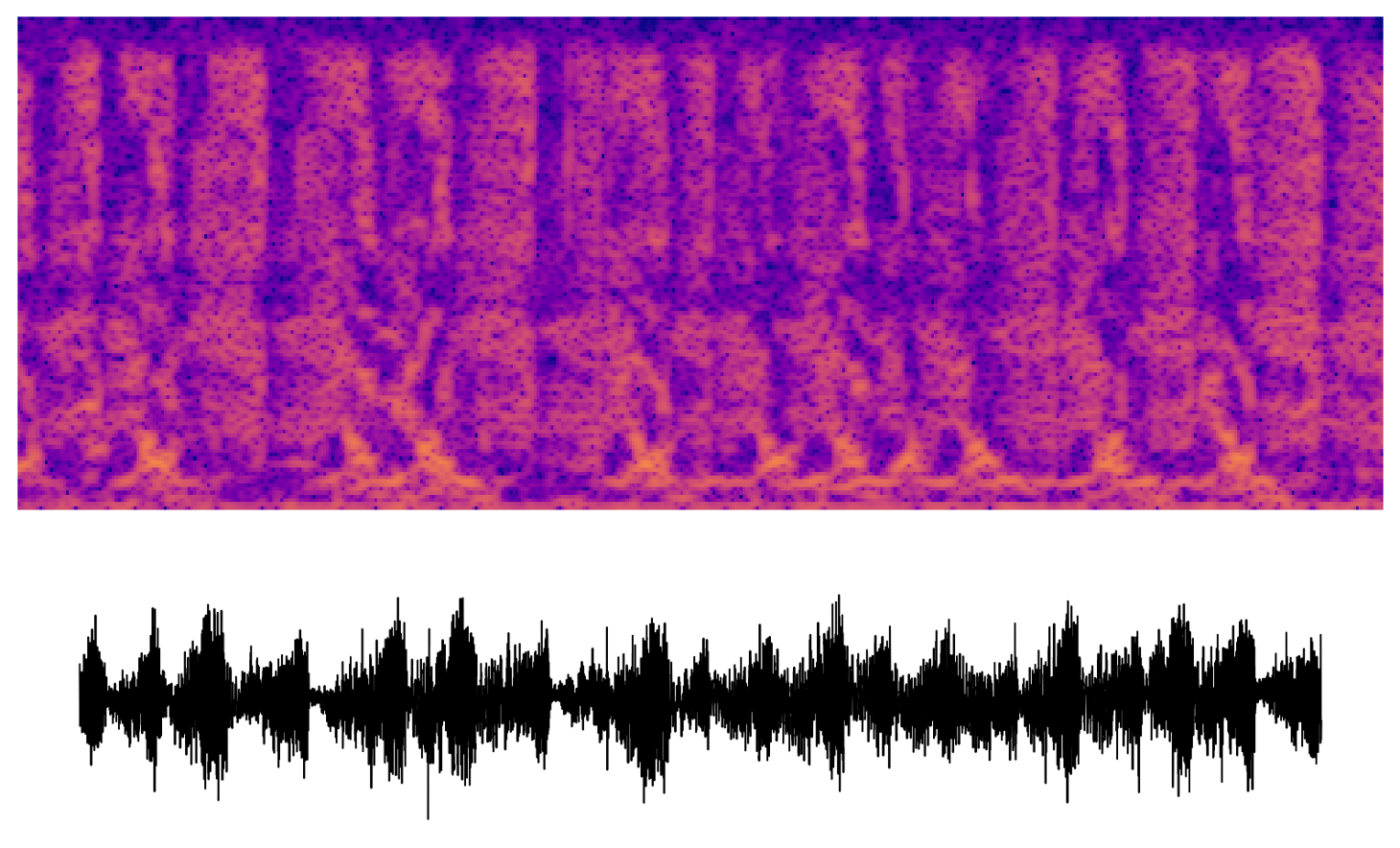
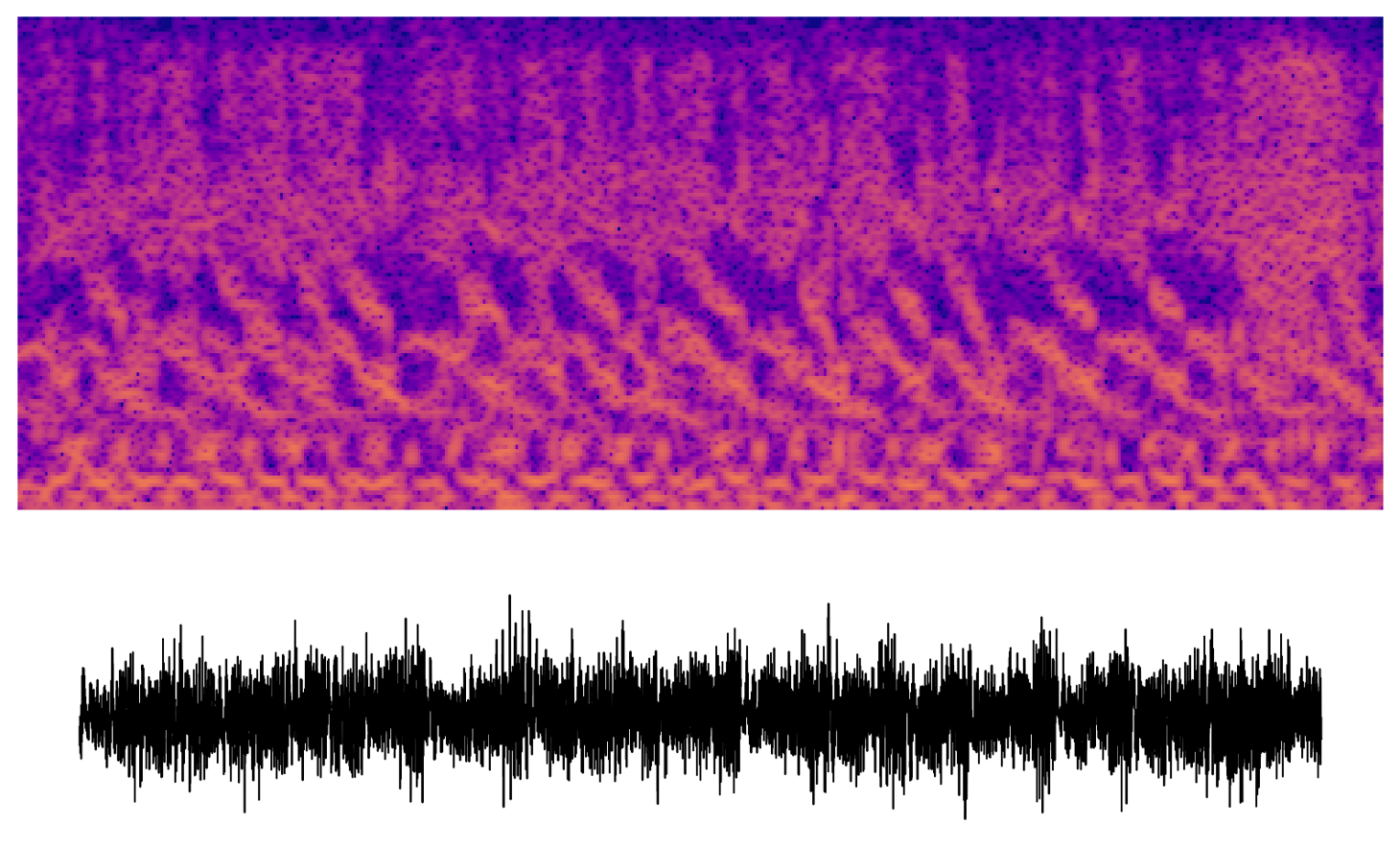
What next?
There seem to be many things to explore regarding interpretability for audio models. For example, we could:
- Retrieve dataset examples of unit activations
- Improve signal-to-noise ratio via regularizers
- Identify paralinguistic features in Wav2Vec2
- Generate multiple samples for a single target, optimizing for diversity
- Long-term consistency: attempt to generate complete words
Acknowledgements
Thanks to Seung-won Park for guidance on modern speech models, Nick Moran for sharing ideas about feature visualization on transformer networks, and Peter Lake for discussing his similar experiments with WaveNet (repo.)
I'm also very grateful to the authors of Distill.pub for providing an overview and contribution to feature visualization techniques and Facebook AI Research for releasing their models.